A fictitious plant ecologist sampled 90 shrubs of a dioecious plant in a forest, and each plant was classified as being either male or female. The ecologist was interested in the sex ratio and whether it differed from 50:50. The observed counts and the predicted (expected) counts based on a theoretical 50:50 sex ratio follow.
Format of fictitious plant sex ratios - note, not a file
Expected and Observed data (50:50 sex ratio).
Female
Male
Total
Observed
40
50
90
Expected
45
45
90
Note, it is not necessary to open or create a data file for this question.
Q1-1.
First, what is the
appropriate test
to examine the sex ratio of these plants?
Q1-2. What null hypothesis is being tested by this test?
Q1-3. What are the degrees of freedom are associated with this data for this test?
Q1-4. Perform a Goodness-of-fit test
to test the null hypothesis that these data came from a population with a 50:50 sex ratio (hint). Identify the following:
Show code
> chisq.test(c(40, 50))
Chi-squared test for given probabilities
data: c(40, 50)
X-squared = 1.1111, df = 1, p-value = 0.2918
X2 statistic
df
P value
Q1-5. What are your conclusions (statistical and biological)?
Lets now extend this fictitious endeavor. Recent studies on a related species of shrub have suggested a 30:70 female:male sex ratio.
Knowing that our plant ecologist had similar research interests, the authors contacted her to inquire whether her data contradicted their findings.
Q1-6. Using the same observed data,
test the null hypothesis
that these data came from a population with a 30:70 sex ratio (hint).
From a 30:70 female:male sex ratio, what are the expected frequency counts of females and males from 90 individuals and what is the X2 statistic?.
Show code
> chisq.test(c(40, 50), p = c(0.3, 0.7))
Chi-squared test for given probabilities
data: c(40, 50)
X-squared = 8.9418, df = 1, p-value = 0.002787
> chisq.test(c(40, 50), p = c(0.3, 0.7))$exp
[1] 27 63
Expected number of females
Expected number of males
X2 statistic
Q1-7. Do the plant ecologist's data dispute the findings of the other studies? (y or n)
Here is a modified example from Quinn and Keough (2002). Following fire, French and Westoby (1996) cross-classified plant species by two variables: whether they regenerated by seed only or vegetatively and whether they were dispersed by ant or vertebrate vector. The two variables could not be distinguished as response or predictor since regeneration mechanisms could just as conceivably affect dispersal mode as vice versa.
Arrington et al. (2002) examined the frequency with which African, Neotropical and North American fishes have empty stomachs and found that the mean percentage of empty stomachs was around 16.2%.
As part of the investigation they were interested in whether the frequency of empty stomachs was related to dietary items. The data were separated into four major trophic classifications (detritivores, omnivores, invertivores, and piscivores) and whether the fish species had greater or less than 16.2% of individuals with empty stomachs.
The number of fish species in each category combination was calculated and a subset of that (just the diurnal fish) is provided.
Note the format of the data file.
Rather than including a compilation of the observed counts, this data file lists the categories for each individual.
This example will demonstrate how to analyse two-way contingency tables from such data files.
Each row of the data set represents a separate species of fish that is then cross categorised according to whether the proportion of individuals of that species with empty stomachs was higher or lower than the overall average (16.2%) and to what trophic group they belonged.
Q3-1. Generate a cross table
out of the raw data file in preparation for the contingency table (HINT).
Q3-2. Fit the model
(HINT), test the assumptions
(HINT) and, using a
two-way contingency table,
test the null hypothesis that the percentage of empty stomachs was independent of trophic classification
(HINT).
What would you conclude form the analysis?
Write the results out as though you were writing a research paper/thesis. For example (select the phrase that applies and fill in gaps with your results):
The percentage of empty stomachs was (choose the correct option)
trophic classification.
(X2 = ,
df = ,
P = ).
Q3-3. Generate the residuals
(HINT) associated with the above contingency test and complete the following table of standardized residuals.
Show code
> arrington.x2$res
TROPHIC
STOMACH DET INV OMN PISC
<16.2 0.7119647 1.0538695 1.3752759 -3.1615926
>16.2 -1.0669740 -1.5793639 -2.0610342 4.7380678
< 16.2%
> 16.2%
DET
OMN
INV
PISC
Q3-4. What further conclusions would you draw from the standardized residuals?
Here is an example (13.5) from Fowler, Cohen and Parvis (1998). A field biologist collected leaf litter from a 1 m2 quadrats randomly located on the ground at night in two locations - one was on clay soil the other on chalk soil. The number of woodlice of two different species (Oniscus and Armadilidium) were collected and it is assumed that all woodlice undertake their nocturnal activities independently. The number of woodlice are in the following contingency table.
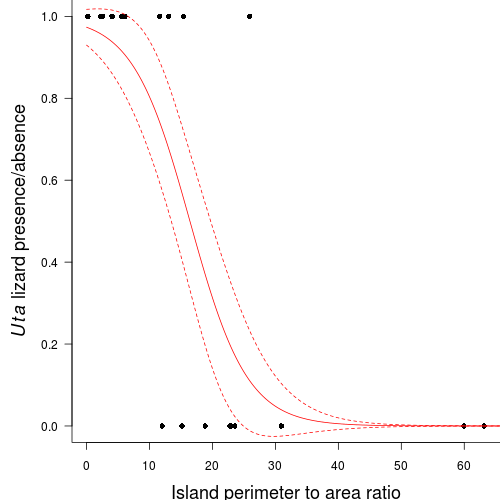
Polis et al. (1998) were intested in modelling the presence/absence of lizards (Uta sp.) against the perimeter to area ratio of 19 islands in the Gulf of California.
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 26.287 on 18 degrees of freedom
Residual deviance: 14.221 on 17 degrees of freedom
AIC: 18.221
Number of Fisher Scoring iterations: 6
sample constant (β0)
sample slope (β1)
Wald statistic (z value) for main H0
P-value for main H0
r2 value (HINT)
Show code
> 1 - (polis.glm$dev/polis.glm$null)
[1] 0.4590197
Q5-3.Another way ot test the fit of the model, and thus test the H0 that
β1 = 0, is to compare the fit of the full model to the reduce model via ANOVA.
Perform this ANOVA (HINT) and identify the following
Q5-4. Construct a scatterplot of the presence/absence of Uta lizards against perimeter to area ratio for the 19 islands
(HINT).
Add to this plot, the predicted probability of occurances from the logistic regression (as well as 66% confidence interval - standard error).
(HINT)
Show code
> par(mar = c(4, 5, 0, 0))> plot(PA ~ RATIO, data = polis, type = "n", ann = F, axes = F)> points(PA ~ RATIO, data = polis, pch = 16)> xs <- seq(0, 70, l = 1000)> ys <- predict(polis.glm, newdata = data.frame(RATIO = xs), type = "response", > se = T)> points(ys$fit ~ xs, col = "red", type = "l")> lines(ys$fit - 1 * ys$se.fit ~ xs, col = "red", type = "l", lty = 2)> lines(ys$fit + 1 * ys$se.fit ~ xs, col = "red", type = "l", lty = 2)> axis(1)> mtext("Island perimeter to area ratio", 1, cex = 1.5, line = 3)> axis(2, las = 2)> mtext(expression(paste(italic(Uta), " lizard presence/absence")), > 2, cex = 1.5, line = 3)> box(bty = "l")
Q5-5.
Calculate the LD50 (in this case, the perimeter to area ratio with a predicted probability of 0.5) from the fitted model
(HINT).
Show code
> -polis.glm$coef[1]/polis.glm$coef[2]
(Intercept)
16.4242
Islands above this ratio are not predicted to contain lizards and islands above this ratio are expected to have lizards.
Q5-6. Examine the odds ratio for the occurrence of Uta lizards.
Show code
> library(biology)> odds.ratio(polis.glm)
Odds ratio Lower 95% CI Upper 95% CI
RATIO 0.8028734 0.659303 0.9777077
Q5-7. What are your conclusions (statistical and biological)?
Q6-2. Fit a log-linear model to examine the interaction between presence of dead coolibah trees and position along
transect HINT) by first fitting a reduced model (one without the interaction,
HINT),
then fitting the full model (one with the interaction,
HINT)
and finally comparing the reduced model to the full model via analysis of deviance (HINT).
Show code
> roberts.glmR <- glm(COUNT ~ POSITION + COOLIBAH, family = poisson, > data = roberts)> roberts.glmF <- glm(COUNT ~ POSITION * COOLIBAH, family = poisson, > data = roberts)> anova(roberts.glmR, roberts.glmF, test = "Chisq")
Q7-2. Log-linear models for three way tables have a greater number of interactions and therefore a greater number of combinations of terms that should be tested. As with ANOVA, it is the higher level interactions (three way) interaction that is of initial interest, followed by the various two way interactions.
Test the null hypothesis that there is no three way interaction (the cause of death is independent of sex and bone marrow type).
First fit a reduced model (one that contains all two way interactions as well as individual effects but without the three way interaction,
HINT),
then fitting the full model (one with the interaction and all other terms,
HINT)
and finally comparing the reduced model to the full model (HINT).
Show code
> sinclair.glmR <- glm(COUNT ~ SEX:DEATH + SEX:MARROW + MARROW:DEATH + > SEX + DEATH + MARROW, family = poisson, data = sinclair)> sinclair.glmF <- glm(COUNT ~ SEX * DEATH * MARROW, family = poisson, > data = sinclair)> anova(sinclair.glmR, sinclair.glmF, test = "Chisq")
Analysis of Deviance Table
Model 1: COUNT ~ SEX:DEATH + SEX:MARROW + MARROW:DEATH + SEX + DEATH +
Q7-3. We would clearly reject the null hypothesis of no three way interaction.
As with ANOVA, following a significant interaction it is necessary to slip the data up according to the levels of one of the factors and explore the
patterns further within the multiple subsets.
Sinclair and Arcese (1995) might have been interesting in investigating the associations between cause of death and marrow type separately for each sex.
Split the sinclair data set up by sex. (HINT)
Perform the log-linear modelling for the associations between cause of death and marrow type separately for each sex.
Show code
> sinclair.glmR <- glm(COUNT ~ DEATH + MARROW, family = poisson, > data = sinclair.split[["FEMALE"]])> sinclair.glmF <- glm(COUNT ~ DEATH * MARROW, family = poisson, > data = sinclair.split[["FEMALE"]])> anova(sinclair.glmR, sinclair.glmF, test = "Chisq")
#Alternatively, the splitting and subsetting can be performed inline
#I shall illustrate this with the MALE data
> sinclair.glmR <- glm(COUNT ~ DEATH + MARROW, family = poisson, > data = sinclair, subset = sinclair$SEX == "MALE")> sinclair.glmF <- glm(COUNT ~ DEATH * MARROW, family = poisson, > data = sinclair, subset = sinclair$SEX == "MALE")> anova(sinclair.glmR, sinclair.glmF, test = "Chisq")
Q7-4. It appears that there are significant interactions between cause of death and bone marrow type for both females and males.
Given that there was a significant interaction between cause of death and sex and bone marrow type, it is likely that the nature of the two way interactions in females is different to the two way interactions in males.
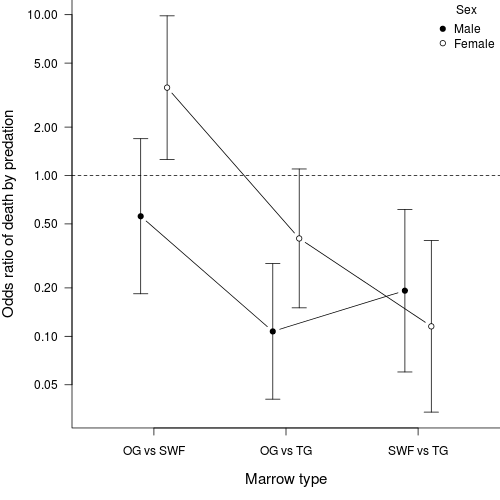
To explore this further, we will examine the odds ratios for each pairwise comparison of bone marrow type with respect to predation level (for each sex)!. Calculate the odds ratios for wildebeest killed by predation for each pair of marrow types separately for males and females
.
Show code
> library(epitools)> library(biology)> female.tab <- xtabs(COUNT ~ DEATH + MARROW, data = sinclair.split[["FEMALE"]])> female.odds <- oddsratios(t(female.tab))> female.odds
A marine ecologist was interested in investigating whether hermit crabs on North Stradbroke Island (what a wet ecologist does on holidays I guess!). He intended to score shells according to whether or not they were occupied and whether they what type of gastropod they were from (Austrocochlea or Bembicium). Shells with living gastropods were to be ignored. Essentially, the NERD wanted to know whether or not hermit crabs occupy shells in the proportions that they are available. A quick count of shells on the rocky shore revealed that approximately 40% of available gastropod shells were occupied and that Austrocochlea or Bembicium shells were approximately equally available.
The ecologist scratched his sparsely haired scalp, raised one eyebrow and contemplated performing a quick power analysis to determine how many observation would be required to have an 80% chance of detecting a 20% preference for Austrocochlea shells.
This task is best broken down into parts.
Q8-1. First we compile what is know about the availability of shells:
Create a variable that contains the proportion of occupied shells and another that contains the proportion of unoccupied shells (HINT, HINT).
Now create two variables that contains the proportion of Austrocochlea and Bembicium shells respectively (HINT, HINT).
Next create a table of proportions that reflect the null hypothesis situation - that is, the proportions expected when hermit crabs show no preferences at all. (HINT, HINT). Provide row (HINT) and column (HINT) titles for this table. Examine this table (HINT)
Now create a variable that contains the anticipated deviance from the null hypothesis - the proportion (20%=0.2) by which the preferences of the hermit crabs deviate from the null hypothesis (HINT).
Use this deviance to calculate the expected proportions when this alternative hypothesis (H1) is true (HINT, HINT, HINT). Examine this table (HINT)
Calculate the effect size (HINT).
Calculate appropriate degrees of freedom (HINT).
Finally, we can calculate the approximate number of total observations needed to have an 80% chance of detecting the 20% preference (HINT). How many gastropod shells need to be sampled?