Here is a little experiment for you to try:
| Action | Explanation |
|---|---|
telnet www.csse.monash.edu.au 80
| Telnet to some world wide web server (80 is the usual port number) |
GET /index.html HTTP/1.0 | GET followed by the local address of some HTML page; GET is normally issued by a web browser but you can do it yourself. HTTP/1.0 is the original and simplest http protocol. Terminate with 2 carriage returns. |
| The web server will send the contents of the page and then close the connection. |
And what you get back is:
HTTP/1.1 200 OK
Date: Thu, 10 Jul 1997 04:01:56 GMT
Server: Apache/1.2.0
Last-Modified: Tue, 08 Jul 1997 05:17:20 GMT
ETag: "6e94-19d1-33c1cd60"
Content-Length: 6609
Accept-Ranges: bytes
Connection: close
Content-Type: text/html
<HTML>
<HEAD>
<TITLE>Department of Computer Science,
Monash University: Home page</TITLE>
</HEAD>
<BODY BGCOLOR="#FFFFFF" TEXT="#000000"
LINK="#0000EE" VLINK="#0000EE"
ALINK="#FF0000">
<CENTER>
<IMG SRC="/images/cs/hp_title.gif" WIDTH=523 HEIGHT=209
ALT="Department of Computer Science, Monash University">
...
...
Note in particular the
line Content-Type: text/html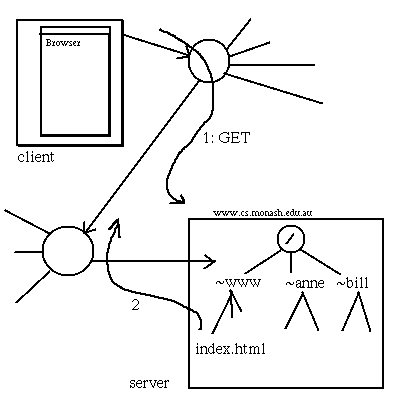
When someone clicks on a link in a web-browser, or requests an HTML page from a given URL, a connection is made over the internet to the specified port on a host or server-computer. The connection is to a web-server program, such as Apache, running on the server computer. The browser and the server communicate using the http protocol.
The browser, running on the client computer,
sends a GET request for the page.
The server returns some header information -
date last modified etc. and the content-type
followed by the contents of the page (file).
http://www.csse.monash.edu.au:80/index.html
^^^^^^^^^^^
file or page name
^^
port number; 80 is the default
^^^^^^^^^^^^^^^^^^^^^^
server-computer, host
^^^^
protocol
The default port for http is `80' and it is usually omitted and taken as read.
The connection and GET can even be done
without a web browser, just using telnet - see above.
The web-server program runs as some user on the server computer, e.g. as user `www'. This user does not have any special privileges; it is not root! It presents to the outside world a view of some directory structure(s) starting at the first slash (/) after the host and port in the URL. This will not in general be equal to "root" (/) within the file system of the computer on which the web-server program runs.
In the diagram above, what the operating system on the server computer
sees as ~www/ is seen by the outside wide world through http
as /.
However, web servers can be configured to determine
what file systems and directories are displayed through the web.
Cgi programs (see later) also run as the user `www'. Other "real" users need to understand this and to note that such a program will therefore assume that any files it uses also belong to `www' unless they are referred to by their full path names.
If the requested web page belongs to the user www,
the server will find it within www's own files.
If the page belongs to some other "real" user,
http://www.csse.monash.edu.au/~lloyd/
It is customary for there to be some convention
where other users place their world wide web files in particular location,
e.g. in a subdirectory called public_html,
so that these and only these files are allowed to be transmitted
as part of the world wide web.
Unix, and many other operating systems, have protection bits
for all files covering, e.g. read, write, execute permission,
for self, group and "world".
However, world means "any user on this computer";
it does not really mean the wide world.
In many ways one would like to be able to set permissions covering
self, group, other local users and (really) world.
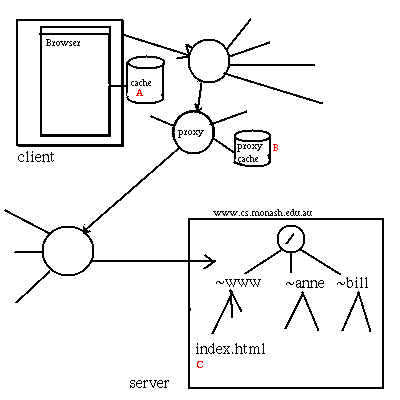
The process of getting a page is usually more complex than was sketched above - all on the grounds of efficiency: The web browser keeps a cache of pages, images etc. and will use a copy of the page from the cache if it can (A).
Browsers can also use a proxy server. This is a pseudo-server, usually on a local computer, that keeps what is in effect a vary large collective cache for those who use it (B). Results from cgi-bin programs are generally not kept in a cache or a proxy.
If a page or image is not in the proxy, the proxy will contact the relevant web-server, pass on a copy to the browser (C) but keep a copy for itself, for a certain time, in case other readers access it.
The use of caches and proxies reduce the amount of traffic on the internet. It does mean that there are multiple copies of data and raises the question of consistency. For many applications it is not essential that all copies of data be absolutely consistent and uptodate, but for some applications it is.
The browser can be configured not to use a proxy for URLs from certain domains - usually local ones where access is quick.
It is possible to set an expires date
on web pages, images etc.,
This can be done by the web-server or
by an author including a META tag in the HEAD
section of an HTML page, e.g.
<META
HTTP-EQUIV="Expires"
CONTENT="Mon, 22 Sep 1997 01:50:52 GMT">
The content can also be a number of seconds,
from the file last being modified, or now.
Once a file has expired it will not be cached.
This mechanism lets an author ensure that readers get
reasonably uptodate versions of files.
However, it can slow down apparent access speed
and should only be used "appropriately".
After all, caches and proxies are there for a reason.
Some web-sites set short or even zero expiry deadlines,
not because their pages change frequently,
but simply to increase the number of "hits".
Because of this, some ISPs now set their proxies to ignore the deadlines.
A web server might keep various logs
recording its http traffic -
access log, referer log, agent log, error log.
Keeping these logs is not a part of the http protocol,
it is just something that most servers can be
optionally configured to do.
Updating the logs takes a certain amount of time,
but more importantly takes a lot of files space.
The logs can be used for page counters, refering statistics,
and browser statistics.
The logs are often read-protected because they contain information that might be sensitive (e.g. cgi-bin parameter values) or of commercial value (e.g. page hits).
The access log keeps records of what machine
accessed what HTML pages and when.
It contains entries such as:
ascend-2-16.cc.monash.edu.au - - [14/Sep/1997:00:16:56 +1000] "GET /~lloyd/tilde/CSC3/CSC3252/Notes/assessment.html HTTP/1.0" 200 10282
ascend-2-16.cc.monash.edu.au - - |
The requesting machine |
[14/Sep/1997:00:16:56 +1000] |
The time and date |
"GET |
The http request |
/~lloyd/tilde/CSC3/CSC3252/Notes/assessment.html |
The page requested |
HTTP/1.0" |
The protocol version |
200 |
The http code |
10282 |
Number of bytes transmitted |
Page-counter values can be computed by scanning the access log.
Note that the access log shows the accessing computer, but does not show the user.
The referer log indicates what page was being viewed
when another page was requested.
Not all browsers set the refering page correctly.
e.g.
http://www.csse.monash.edu.au/~lloyd/tilde/CSC3/CSC3252/ ->
"GET /~lloyd/tilde/CSC3/CSC3252/Notes/assessment.html HTTP/1.0"
http://www.csse.monash.edu.au/~lloyd/tilde/CSC3/CSC3252/ -> |
The refering page. |
"GET /~lloyd/tilde/CSC3/CSC3252/Notes/assessment.html HTTP/1.0" |
The page refered to. |
The referer log can be used to find out where your "hits" are coming from.
The agent log collects the browsers
(or other agents) requesting pages, if set:
This information can be used to determine what browser platforms you need to support most strongly.