^CSE454^
[01]
>>
Information etc.Introduction
CSE454
2005
:
This document is online at
http://www.csse.monash.edu.au/~lloyd/tilde/CSC4/CSE454/
and contains hyper-links to other resources
|
^CSE454^
<<
[02]
>>
InformationDefn: The information in learning of an event `A' of
probability P(A) is
|
^CSE454^
<<
[03]
>>
EntropyEntropy is the average information in a probability
distribution over a sample (data) space S.
H = - SUMv in S {P(v) log2 P(v)}
|
| ^CSE454^
<<
[04]
>>
e.g. Fair coin: P(head) = P(tail) = 1/2; e.g. Biased coin: P(head) = 3/4, P(tail) = 1/4; |
^CSE454^
<<
[05]
>>
Theorem H1if {pi}i=1..N and {qi}i=1..N are probability distributions then
N
SUM { - pi log2(qi) }
i=1
is minimised when qi=pi.
|
^CSE454^
<<
[06]
>>
Kullback Leibler distanceDefn: The K-L distance (also relative entropy) of prob' dist'n {qi} from {pi} is
N pi
SUM pi log2( -- ) >= 0
i=1 qi
NB. >=0 by H1.
Not necessarily symmetric.
|
^CSE454^
<<
[07]
>>
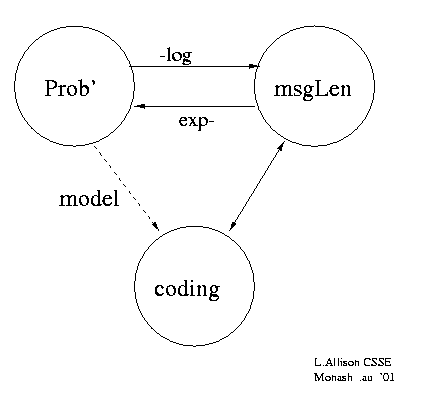
CodingWe work with prefix codes: No code word is a prefix of another code word.
Sender -----------> Receiver
+
source -----> (0|1) -----> source
symbols* encode decode symbols*
Average code-word length, i.e. message length, is
|
^CSE454^
<<
[08]
>>
|
| ^CSE454^
<<
[09]
>>
|
^CSE454^
<<
[10]
>>
Minimum Message Length (MML)If we want to learn (infer) a hypothesis (theory | model) or parameter estimate(s), H, from data D
Note trade-off: complexity of H v. complexity of D|H, both measured in bits, prevents over-fitting; this issue includes precision used to state continuous-valued parameters. |
| ^CSE454^
<<
[11]
>>
. . . MML Sender-receiver paradigm keeps us "honest"
Sender -----------> Receiver
No hidden information passed "under the table".
Safe: Cannot make a hypothesis look better than it really is. |
^CSE454^
<<
[12]
>>
EstimatorsAn estimator is a function from (a training set, i.e.) the sample (data) space, S, to the hypothesis (model, parameter) space H. e: S ---> He.g
different estimators may give different results
in different situations. |
^CSE454^
<<
[13]
>>
PredictionPrediction is different from inference. Inference (learning) is about finding an explanation (hypothesis, model, parameter est') for the data, prediction is about predicting future data and an explanation might or might not help. The best thing that can be done in prediction is to use an average over all hypotheses weighted by their posterior probabilities. © 2005 L. Allison, School of Computer Science and Software Engineering, |