Note that the core (suggested) algorithms for problems A and B are essentially the same:
We store partial results in m[,]. m[p,q] is a partial solution that is constrained to use exactly p [lines or segments] for q [words or data values].
The solutions [line-breaks or cut-points] can be found by tracing back from m[p,n], retracing backwards the choices made when computing the values in m[,] forward.
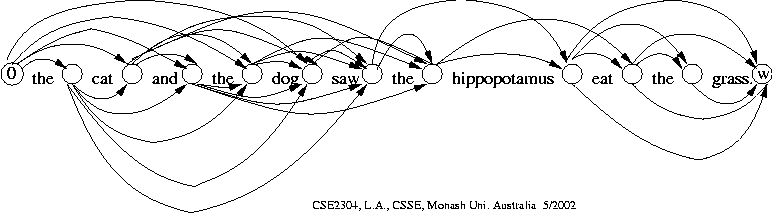
Create a weighted, directed [graph] (it's actually a DAG) with a vertex "in between" each word. The weight of an edge from the vertex before word i to the vertex after word j is the cost of a single line containing exactly the words i to j inclusive (if this is possible). Note that edges into vw have zero cost (last line).
Find the [shortest path] from v0 to vw.
A similar observation can be made about graphs and the
data segmentation problem (group B), but
an edge "over" a single data value has weight zero,
so that is what a shortest-path algorithm will use
unless either