-----JAVASCRIPT IS OFF-----
How much Information can one learn about a Binomial Distribution?
The binomial provides a
simple
example about information,
is
important
, e.g., consider
{+ve,
-
ve},
{true, false},
{H, T},
{purine, pyrimidine},
{hydrophilic, hydrophobic},
. . . ,
and
is a
component
of many
structured
models, e.g.,
Markov model
,
classification tree (etc.),
Bayesian net,
segmentation
(of binary seq. or image)
,
. . .
2-state:
Pr(H) = θ,
0 ≤ θ ≤ 1,
Pr(T) = 1 - θ
Binomial, n trials:
Pr(#H = k) =
n
C
k
θ
k
(1 - θ)
n-k
,
0 ≤ k ≤ n
How much information can one learn about θ? . . .
users.monash.edu.au/~lloyd/Seminars/2009-Binomial/index.shtml
(
BTW the question is important, e.g.,
the win/loss record of an AFL team:
L W L L W L W W L W L W
The team changed coach after round 6.
Has it paid off?
(i) 6 from 12 (null, any difference is due to chance) v.
(ii) 2 from 6 ++ 4 from 6
Including the information of
two distributions, (ii),
v.
just one distribution, (i),
guards against
overfitting
.
)
. . . How much information can one learn about θ? . . .
. . . How much information can one learn about θ?
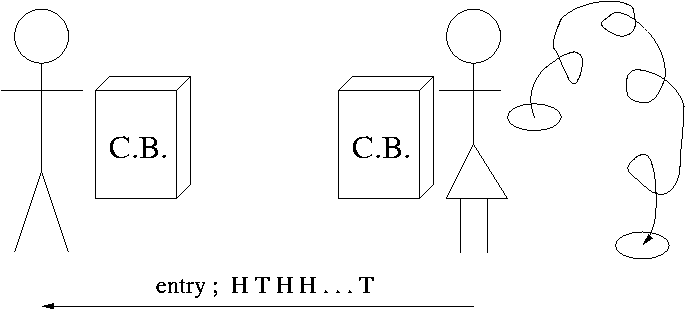
Jack and Jill (devout
Bayesians
)
design a code-book for binomials.
Then, as so often happens, they drift apart . . .
. . . but they do keep in contact.
Jill sends Jack
(i) n,
(ii) C.B. entry,
&
(iii) data | entry.
In (ii) Jill chooses an entry (theory, estimate) for θ out of the code book.
How would Jack and Jill design an optimal code book?
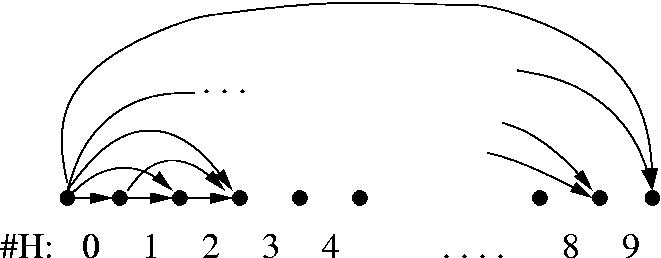
2
n
possible sequences of length n, but
wrt θ, only #H matters.
#H ∈ [0, n].
The book's page for a given 'n' corresponds to a partition of [0, n]
0
1
2
3
. . .
n
simplest
[
. . .
]
. . .
most complex
[
][
][
][
][
. . .
][
]
Generally the extreme possibilities are not optimal.
And they chose a prior for θ
(uniform is simplest option).
There is a polynomial-time algorithm to design the page for 'n':
Complete
DAG (!-)
The
weight
of an edge is the contribution to the
expected
message-length of the corresponding
part
of the partition of [0, n].
Seek the shortest path from far left to far right.
Needs Mozilla Firefox's JavaScript ON!
Demo
:
n=
needs JavaScript on
Observing #H, Jill selects a code book entry (interval [lo, hi], estimate θ) and transmits the entry and the data given that entry.
The amount of information transmitted about θ is
- log( (hi - lo + 1) / (n + 1) ).
Bad news:
There is no polynomial-time algorithm to design the code book for the multinomial if
k = |{Values}| ≥ 4,
and
the case for the trinomial is open [1].
Good news:
There are fast algorithms for accurate estimates of the
message-length
for the
multinomial
, and many other useful distributions and models.
[1] G. E. Farr & C. S. Wallace,
The Complexity of Strict Minimum Message Length Inference
, Computer J., 45(3), pp.285-292, 2002.
©
Lloyd Allison
Faculty of Information Technology (Clayton),
Monash University,
Australia 3800.
Created with "vi (Linux & Solaris)", charset=iso-8859-1